Project details
I am a proponent of the hypothesis that superintelligence should be born from the synergy of artificial intelligence, which has a gigantic erudition and trend awareness, with the collective intelligence of real live human experts with real knowledge and experience.
Yann LeCun has a great quote: “Large language models seem to possess a surprisingly large amount of background knowledge extracted from written text. But much of human common-sense knowledge is not represented in any text and results from our interaction with the physical world. Because LLMs have no direct experience with an underlying reality, the type of common-sense knowledge they exhibit is very shallow and can be disconnected from reality”.
LeCun writes about the tricks that can be used to try to teach the LLM common sense about the world, but this is still far from the question of validity, because even if these tricks lead to results, there is still the question of whether the common sense database is valid.
At the moment, all LLM developers claim that their datasets are reliable, but this is obviously not the case, as they have been found to be fake on more than one occasion, and the developers themselves have no criterion for the veracity of the information at all.
The position “my dataset or ontology is trustworthy because it's mine” cannot be the basis of trustworthiness. So the future for me personally is quite simple and is determined by the following logic:
1. The hallucinations and confabulations of artificial intelligence are fundamentally unrecoverable https://www.mdpi.com/1099-4300/26/3/194
2. Cross-training LLMs on each other's hallucinations inevitably leads to “neural network collapse” and degradation of the knowledge of the people who apply them https://arxiv.org/abs/2305.17493v2 and https://gradual-disempowerment.ai
3. Any physical activity in the real world is connected to the physics of the entire universe, and sometimes the slightest mistake in understanding these interrelationships is fatal. A million examples can be seen in industrial safety videos. That is why any hallucination of artificial intelligence without reliance on the real experience of real people with real knowledge of the world will end in mistakes and losses of varying degrees for the humans, up to catastrophic.
Hence the conclusion — people have the main responsibility to connect with reality. And the more complex will be the questions that will be solved by neural networks, the more serious will be the human responsibility for timely detection of more and more subtle and elusive hallucinations. This requires people with the deepest knowledge, and not the knowledge memorized under pressure at school, but with real experience on almost any issue.
How many tasks neural networks will have, there should be so many superprofessionals on these tasks. And for the superprofessionals, you just need ordinary professionals and assistant professionals and students of assistant professionals.
And for all this we need a rating of reliability of knowledge to know who is a professional and who is not a professional.
And without information veracity criterion and knowledge validity rating any LLM (and in general any artificial system according to Michael Levin's proof) will face imminent collapse.
Only the collective neural network of all the minds of humanity can be opposed to artificial intelligence. For mutual verification and improvement of LLMs and humans, we need the ability to compare the knowledge of artificial intelligence with collective intelligence. This is the only thing that can get us out of the personal tunnels of reality and personal information bubbles in which we are getting deeper and deeper stuck individually.
All this is aggravated by the fact that all factchecking in information technologies is now based solely on the principle of verification (i.e. confirmation). But this approach becomes unacceptable in modern conditions after the superiority of AI over humans and should be fundamentally replaced by the principle of falsifiability. It means that the verification of the meaningfulness and then the veracity of hypotheses should be carried out not through the search for facts that confirm them, but mainly (or even exclusively) through the search for facts that refute them. This approach is fundamental in the scientific world, but for some unknown reason it has not been implemented anywhere in information technologies until today.
I strongly believe that reputation and trust are based on people saying what they do and doing what they say, so a key element for this whole scheme to work is the need for an independent system to objectively and unbiasedly verify the veracity of information and compare any existing opinions for mutual consistency and noncontradiction. And such a system must satisfy to the highest principles of scientific honesty:
— the system must be completely independent of admins, biased experts, special content curators, oracles, certificates of states and corporations, clickbait likes/dislikes or voting tokens that can bribe any user
— the system should be global, international, multi-lingual and free of charge to be accessible for users all over the world
— the system should be unbiased to all authors and open to the publication of any opinions and hypotheses
— the system must be objective and purely mathematically evaluate all facts and arguments without exception according to the principle of "all with all" immediately the moment they were published
— the system must be decentralized and cryptographically secured insuring that even its creators have no way of influencing the veracity and reputation
— the system should be available for audit and independent verification at any time.
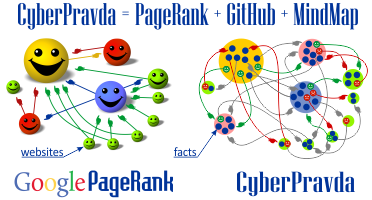
The technical solution is a discussion platform for crowdsourcing reliable information with a monetization ecosystem, game mechanics, and a graph theory based algorithm that objectively compares all existing points of view. It is a combination of existing technologies that are guaranteed to meet all requirements of objectivity and unbiasedness:
— it is built on a blockchain with an independent mathematical algorithm for analysis of the veracity of arguments on the basis of graph theory with auto-translation of content into 109 languages
— credibility arises only from the mutual influence of at least two different competing hypotheses and does not depend on the number of proponents who defend them
— credibility arises only from the mutual competition of facts and arguments and their interactions with each other
— the only way to influence credibility in this system is to publish your personal opinion on any topic, which will be immediately checked by an unbiased mathematical algorithm for consistency with all other facts and arguments existing in the system
— each author in the system has personal reputational responsibility for the veracity of published arguments.
Algorithm is based on the principle that for some facts and arguments people are willing to bear reputational responsibility, while for others they are not. The algorithm identifies these contradictions and finds holistically consistent chains of scientific knowledge. And these are not likes or dislikes, which can be manipulated, and not votes, which can be falsified. Each author publishes his own version of events, for which he is reputationally responsible, not upvoting someone else's.
In the global hypergraph, any information is an argument of something one and a counterargument of something else. Different versions compete with each other in terms of the value of the flow of meaning, and the most reliable versions become arguments in the chain of events for facts of higher or lower level, which loops the chain of mutual interaction of arguments and counterarguments and creates a global hypergraph of knowledge, in which the greatest flow of meaning flows through stable chains of consistent scientific knowledge that best meet the principle of falsifiability and Popper's criterion.
The algorithm is based on the fact that scientific knowledge is noncontradictory, while ignorames, bots and trolls, on the contrary, drown each other in a flood of contradictory arguments. The opinion of a flat Earth has a right to exist, but it is supported by only one line from the Bible, which in turn is not supported by anything, yet it fundamentally contradicts all the knowledge contained in textbooks of physics, chemistry, math, biology, history and millions of others.
The algorithm up-ranks facts that have confirmed evidences with extended multiple noncontradictory chains of proven facts, while down-rating arguments that are refuted by reliable facts confirmed by their noncontradictory chains of confirmed evidences. Unproven arguments are ignored, and chains of statements that are built on them are discarded.
The algorithm has natural self-protection from manipulations, because regardless of any number of authors each fact in the decentralized database is one single information block and regardless of any number of opinions any pair of facts is connected by one single edge. The flow of meaning in the logical chain of the picture of events does not depend on its length, and unreasonable branching of the factual statement leads to the separation of the semantic flow and reduces the credibility of each individual branch, for which we have to prove its veracity anew.
Similar to Wikipedia, the algorithm creates articles on any controversial topic, which are dynamically rearranged according to new incoming evidences and desired levels of veracity set by readers in their personal settings ranging from zero to 100%. As a result, users have access to multiple Wikipedia-like articles describing competing versions of events, ranked by objectivity according to their desired credibility level, and the smart contract allows them to earn money by betting on different versions of events and fulfilling orders to verify their veracity.



Join the Discussion (0)
Please create account or login to post comments.