

Rob Freeman
Project OwnerProject Leader Managing the grant, and looking for the right collaborative synergies.
DEEP Connects Bold Ideas to Real World Change and build a better future together.
Coming Soon
Milestone Release 1 |
$15,000 USD | Transfer Complete | 15 May 2025 |
Milestone Release 2 |
$10,000 USD | Transfer Complete | 05 Jun 2025 |
Milestone Release 3 |
$20,000 USD | Transfer Complete | TBD |
Milestone Release 4 |
$20,000 USD | Pending | TBD |
Milestone Release 5 |
$10,000 USD | Pending | TBD |
Milestone Release 6 |
$4,999 USD | Pending | TBD |
Milestone Release 7 |
$1 USD | Pending | TBD |
An experiment to test whether symbolic cognitive structure can be made to emerge simply as chaotic attractors in a network of observed language. This experiment is an extension of earlier work which: 1) Demonstrated partial structuring of natural language from ad hoc (chaotic?) re-structurings of vectors. 2) Demonstrated spontaneous oscillations in a network of language sequences. The core idea posits neuro-symbolic integration has eluded us because what we perceive as symbolic order in the world, may actually be chaotic attractors on what is a fundamentally multiply interpretable, reality. If that is so, full neuro-symbolic integration may be easy, we just have to embrace the chaos.
This RFP invites proposals to explore and demonstrate the use of neural-symbolic deep neural networks (DNNs), such as PyNeuraLogic and Kolmogorov Arnold Networks (KANs), for experiential learning and/or higher-order reasoning. The goal is to investigate how these architectures can embed logic rules derived from experiential systems like AIRIS or user-supplied higher-order logic, and apply them to improve reasoning in graph neural networks (GNNs), LLMs, or other DNNs.
In 2022 Ben Goertzel commented in a session of the AGI Discussion Forum:
"For ... decades, which is ridiculous, it's been like, OK, I want to explore these chaotic dynamics and emergent strange attractors, but I want to explore them in a very fleshed out system, with a rich representational capability, interacting with a complex world, and then we still haven't gotten to that system ... Of course, an alternative approach could be taken as you've been attempting, of ... starting with the chaotic dynamics but in a simpler setting. ...
This project is an opportunity for the Primus architecture to take a glance also at that alternative approach, and explore its possibilities.
In more detail
In a major departure from all work to date, we assume natural language grammar is chaotic. So it cannot be abstracted, only generated constantly anew.
To perform this constant, dynamic, expansion of grammatical structure, we encode large bodies of text from a language in a network of word sequences. This is easy to do:
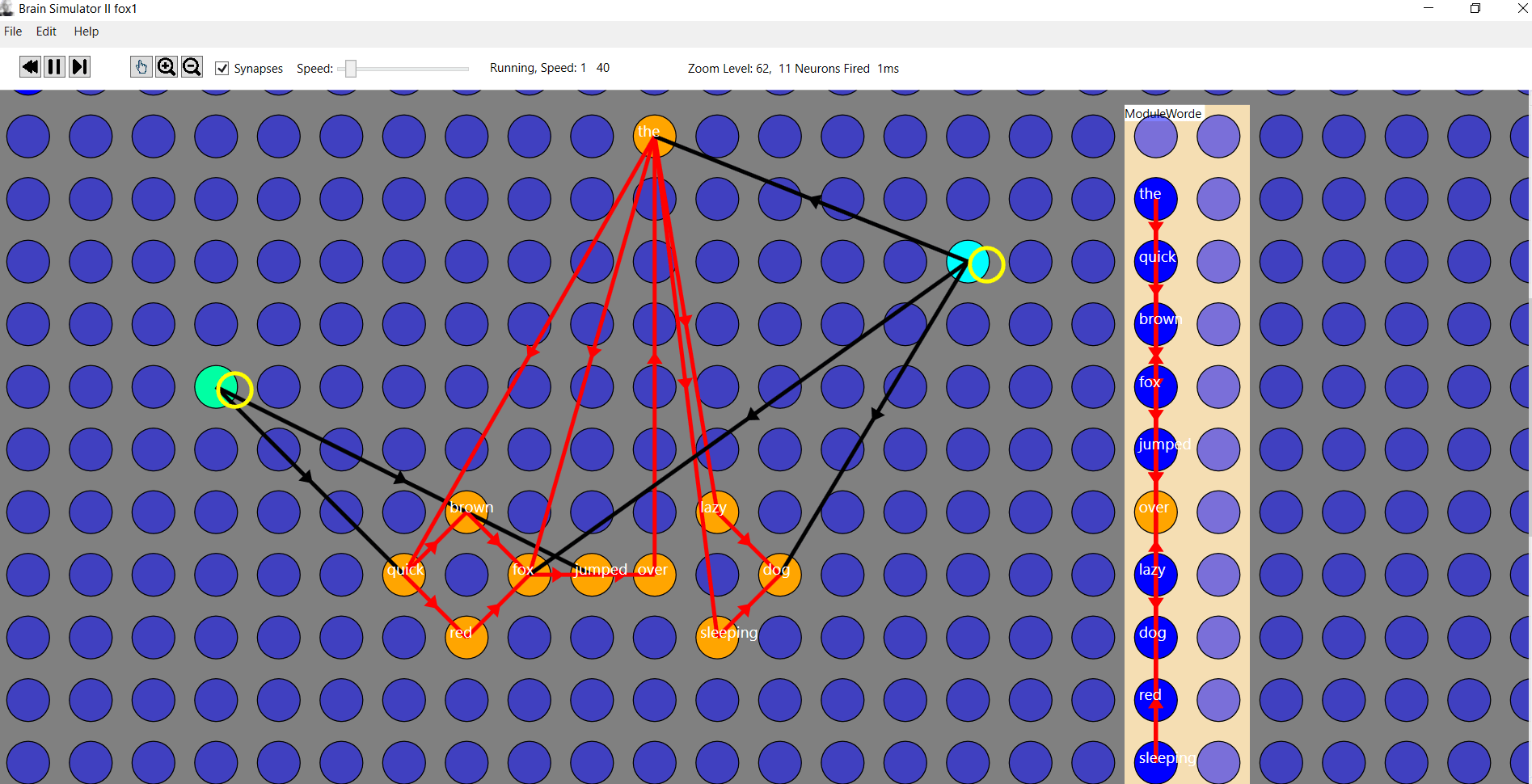
Then we seek to cluster grammatical patterns, constantly anew, in real time, by setting the network oscillating and seeing which parts of the network synchronize their oscillations.
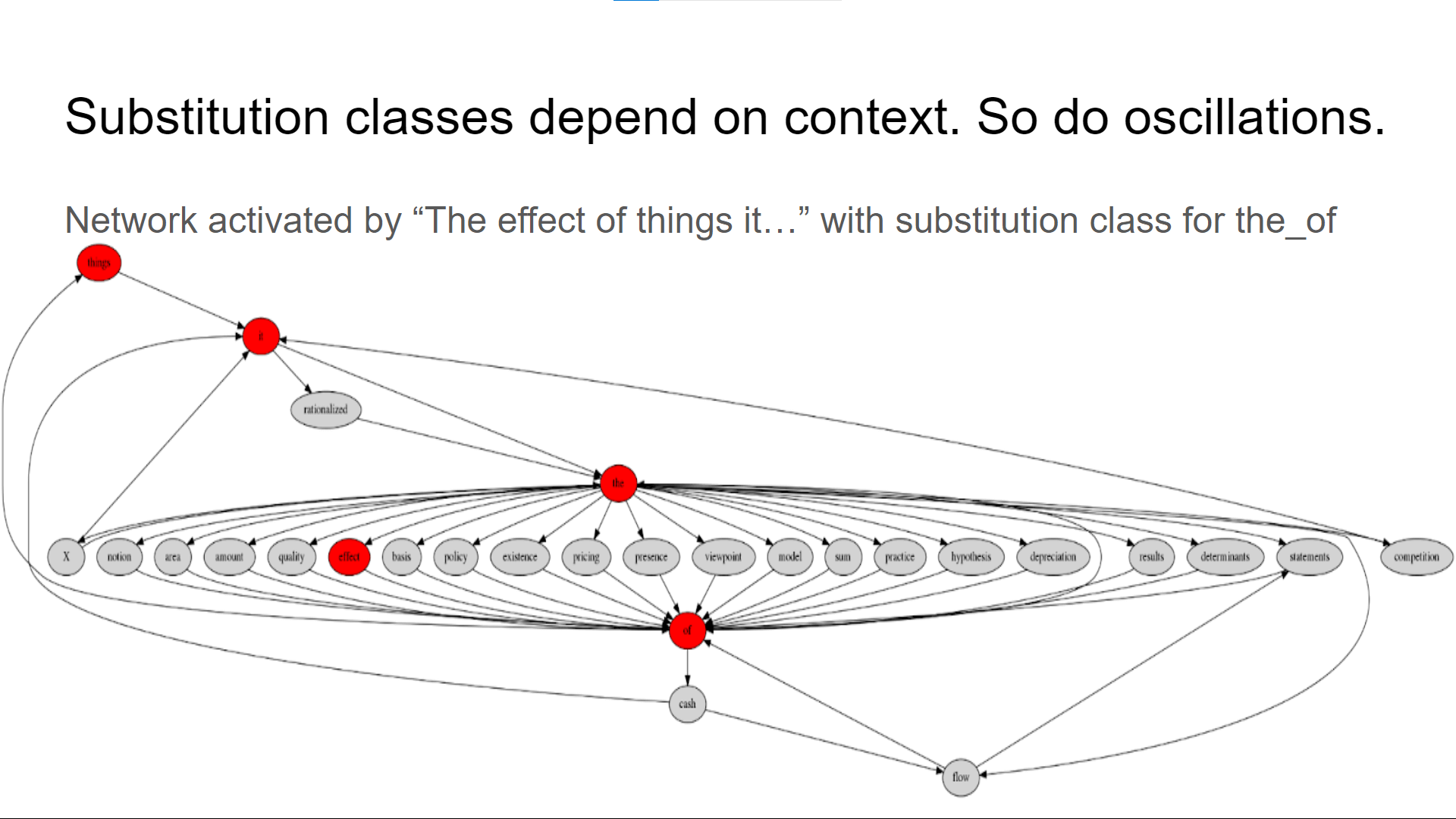
The network should generate a raster plot of words and groups of words which share similar contexts:

The information of shared context will be coded automatically in the network of word sequences from the language. Words and word groups which share contexts will be more tightly connected, and tend to synchronize their oscillations.
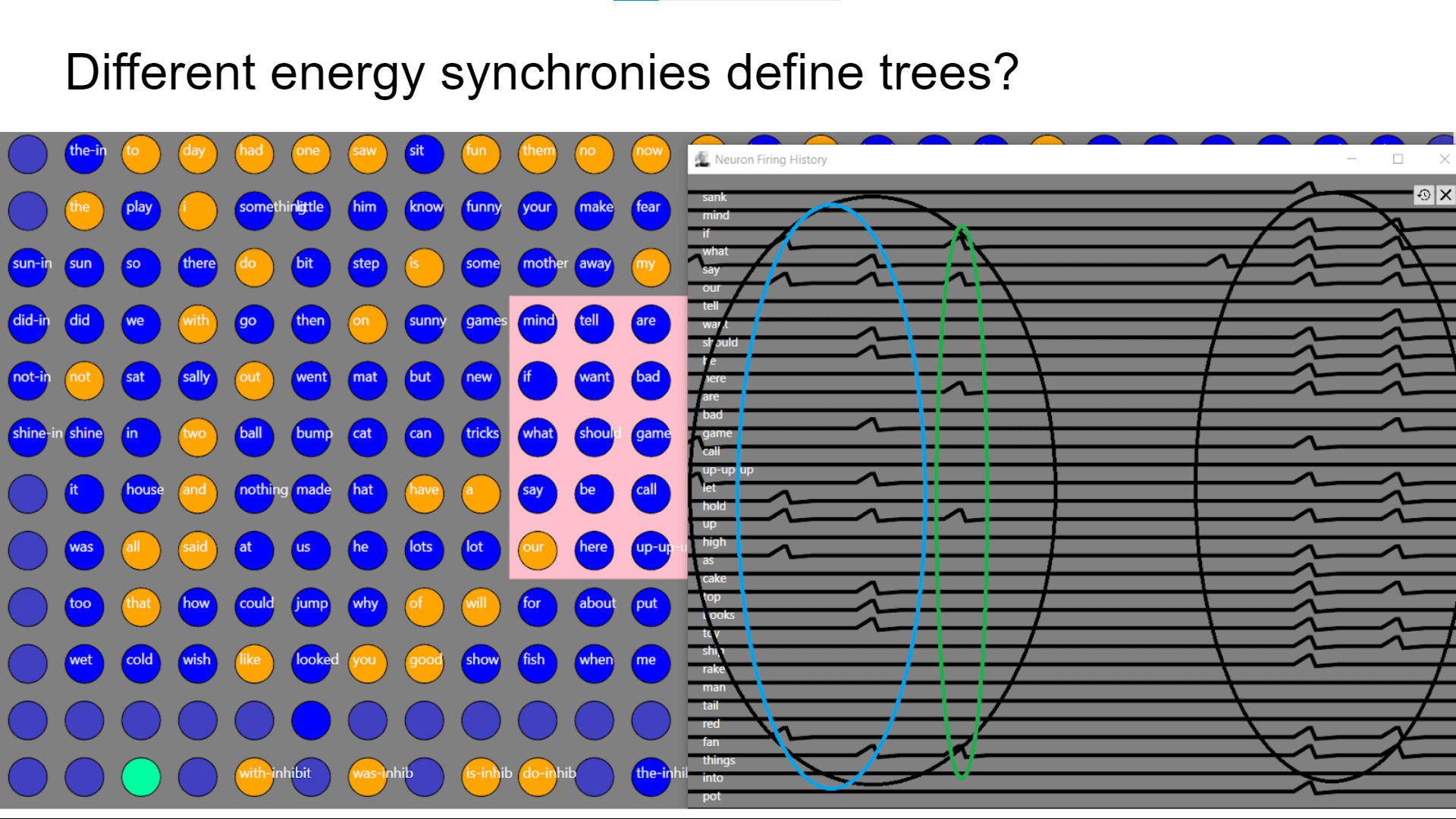
Further, nested hierarchies of such synchronized groups of nodes might be expected to form trees which reveal meaningful language structure:
An earlier vector implementation of this chaotic, dynamic structuring, idea, did generate meaningful hierarchies comparable to parse structure:
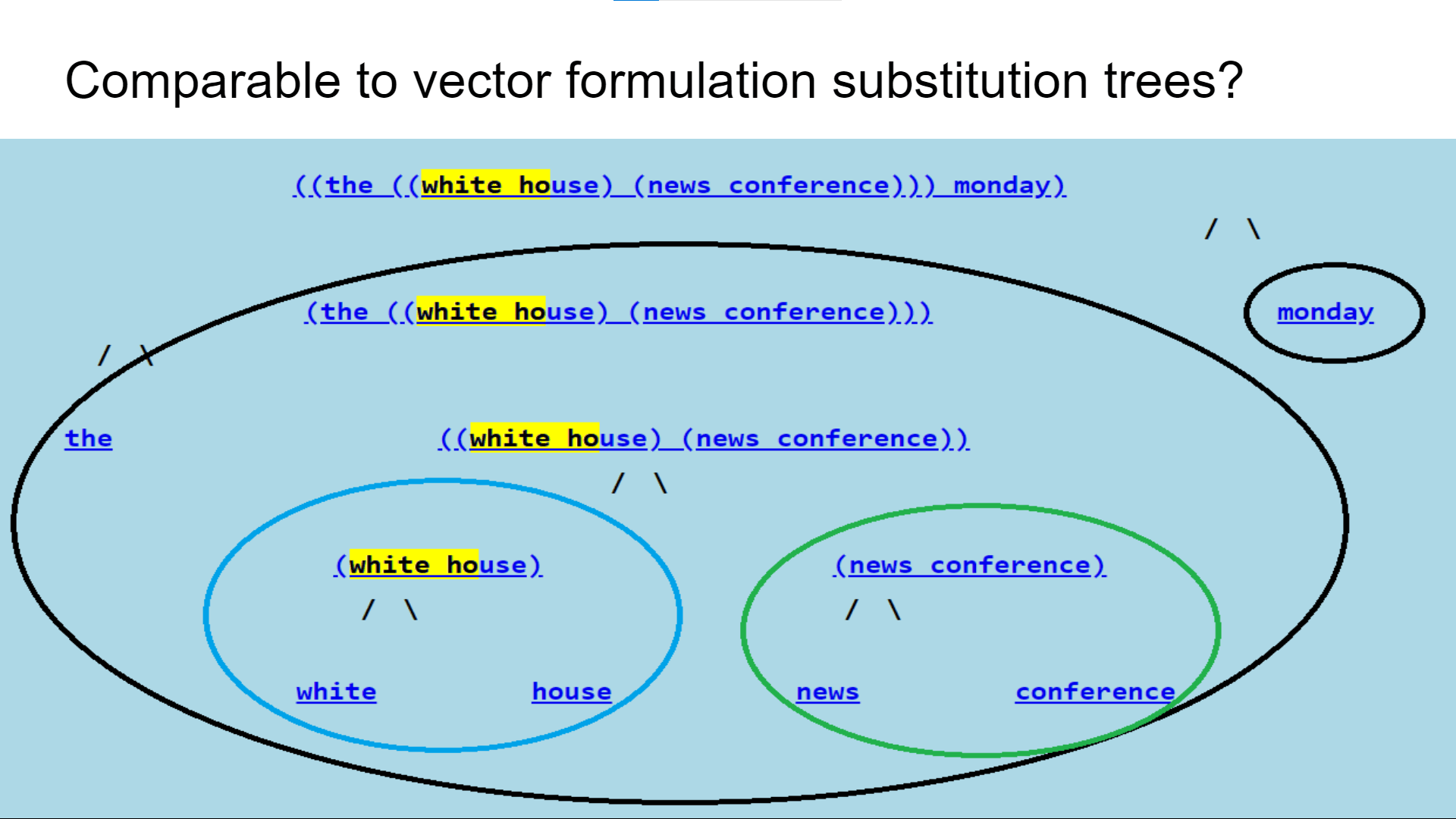
This is initially attempted for natural language as a simplified problem. But it is expected the underlying principles will extend to other perceptual and general concept formation processes.
For instance vision may be linearized as a sequence of fixations (saccades?) and objects identified in similar ways.
It may generally apply to all sensory data, processed in a sequential way, say with feedback learning in the AIRIS system.
Further discussion
The success of Large Language Models these last few years has astounded the world. But people are mystified by the lack of structure. And this seems connected with a broader problem of a lack of "truthiness".
Also these systems puzzle with their enormous size, data, training, and power requirements.
Most proposed solutions are along the lines that we need to add structure using some other kind of data. Typically characterized as "world knowledge", visual, multi-media, physical, or psychological "priors".
The thesis of this project is that there is no Holy Grail, fixed or "primitive" semantic structure to be found in other data. But that instead we should take the very lack of structure exposed by language models as hinting at a solution, rather than a problem, and solve the structure problem by better understanding what language models are trying to tell us. Only then expanding the solution to other data.
Instead of lamenting the lack of symbolic structure in language models. One way to look at the history of AI is to see it as a constant movement away from stable structure. The progress of AI has been from first symbolic models and logic, then to statistical models, then to supervised, distributed, models, then unsupervised, distributed, models. And most recently to unsupervised, distributed, sequence prediction (language) models. So progress has been constantly towards less structure. Until with language models, finally, all attempt at structure is abandoned completely, in favour of prediction alone. And, surprise surprise, ignoring structure completely, performs best of all.
This seems a paradox.
Somehow addressing the language problem, has led us to a cognitive modeling that has the least structure, but works better for it.
What is it that the language modeling problem is tring to tell us?
I think the answer is that the language modeling problem is trying to tell us that cognitive structure is not the finite, stable, set of primitives we have imagined it to be. That actually it is attractors in a chaotic dynamical system. The very largeness of language models is telling us that we seem to have no structure, because we have a chaotic abundance of it. All crushed in together, opaquely. And that we are burning a hole in the planet attempting to expand it all in one massive training step. When actually the way to generate it clearly and cheaply, is to allow the chaotic system to respond naturally to context from moment to moment. And generate its complexity spread over time, expressed as creativity, instead of all crushed in together, and simplified because of it.
In a word I think the history of AI has been a movement away from stable structure, because cognitive structure is chaotic.
The solution to this would not be limited to language. But as with Large Language Models, the path to modeling it may still lie most naturally through the language problem.
This project proposes that we fully explore this proposed chaotic character to cognitive structure exposed by language. In the expectation that the same techniques will be relevant for broader cognition, the question of what "objects" are, what "truth" is, vision, balance, and indeed, reason.
In the context of the Hyperon system, particularly one bridging deep neural nets and symbolic reasoning, it might be said to interpose itself possibly even below an "atom" space. So not just interfacing with an atom space, but ever constructing and reconstructing, an atom space.
Everything else in the reasoning system might remain the same. It might still perform its pattern matching operations. Or any kind of formal reasoning over the resolution of perceptual space into "atoms". With the constantly reconstructed atom space assisting it, in a sense, by resolving the world into a sense of "objects" relevant to one question or another, in a sense posing "better questions".
In practical terms it is suggested these benefits might be obtained in the simplest way possible, by essentially using the same "learning" principles that are used in LLMs now. And "learning" the same patterns. But contrasted only by now anticipating that the patterns learned might be chaotic. And finding them from moment to moment at run time, rather than in one massive training phase.
We might do this easily, because language models lead us to conceive the structuring problem as one of cause & effect prediction. This compared to earlier iterations of neural networks, tied first to fixed external patterns with surpervised learning, or fixed internal patterns with unsupervised learning. By contrast LLMs learn predictive symmetries. And predictive symmetries are not only free to vary so long as they continue to predict, but as symmetries they don't require an estimation of error at all. We can find predictive symmetries without back propagation.
And actually a natural way to do this may be by some kind of "vibration analysis". Vibrations being an excellent way to detect symmetries.
So, in the concrete, this project proposes that we attempt to merge neuro and symbolic in the Hyperon system, by replacing backprop in existing LLMs, and instead finding the same predictive symmetries, only in real time, changing (chaotically) from moment to moment, using some kind of oscillatory "vibration analysis". The result forming a new network of "atoms", also changing from moment to moment (and a basis for combining/merging atoms), to be used by Hyperon to perform the graph analysis and pattern matching which it is naturally adpated to do, as a graph based reasoning system.
Overall

 3.6
3.6
3.8
3.6
3.6
3.8
New reviews and ratings are disabled for Awarded Projects
Overall
3.0
3.0
0.0
Overall
5.0
5.0
0.0
Bold vision and alignment with the RFP’s goals. Lack of detailed technical and experimental plans are concerns. Given the credibility of the researcher this project could be a high-risk, high-reward candidate for funding.
Overall
1.0
1.0
0.0
"Until with language models, finally, all attempt at structure is abandoned completely, in favour of prediction alone. And, surprise surprise, ignoring structure completely, performs best of all." This seems to be a misinterpretation of key results, since attention heads allow to learn multiple structures that matter for an output (e.g. relevant prior words in a sentence to predict a target word), that is part of why they work so well. This approach which dismisses Transformer models seems suspicious to me, and due to the further lack of technical details I gave a low rating. If it would build on top of Transformer it could be a different story, for instance it was quite relevant (but only in light of Transformers and the LLM's) what they found in Bhargava, A., Witkowski, C., Looi, S. Z., & Thomson, M. (2023). What's the Magic Word? A Control Theory of LLM Prompting. arXiv preprint arXiv:2310.04444.
Overall
4.0
5.0
0.0
Freeman is a known entity and a serious researcher and in his own way a visionary thinker. He has been brewing these ideas for a long time. It would be cool to see him experiment with his creative directions in Hyperon. OTOH in the first instance it's not a general-purpose neural-symbolic learning method, it's a novel computational-linguistics idea with deep cognitive/philosophical underpinnings. It might have implications/value beyond language as well.
Overall
5.0
5.0
0.0
Interesting idea with potential for complex systems emergence. Con: unproven and speculative.
Get sequence network oscillating and identifying more tightly clustered subnetworks: Select platform: Option 1: Get clustering working in sequence network with old neurosimulator code from paper: https://ncbi.nlm.nih.gov/pmc/articles/PMC3390386/ Code here: https://modeldb.science/144502 Option 2: Alternatively extend already existing implementation of oscillating sequence network in Github project: https://discourse.numenta.org/t/the-coding-of-longer-sequences-in-htm-sdrs/10597/27 Which is chosen might depend on the experience of coders hired for the task. Sketching one month timeline to incorporate project starting and admin wrinkles.
Project platform established.
$15,000 USD
Get neurosimulator oscillating in network formed from a moderate sized language corpus. Option 1: Brown Corpus Option 2: British National Corpus Also sketching timeline of one month for this. It might not be too hard but allowing some time for problems. Likely problems might be issues with the size of a corpus network. It might require hardware upgrades or adjustments.
Input language connectivity for a sufficiently large language sample.
$10,000 USD
This is the first major research question. It may be tricky. This is the major first step not yet achieved for other code and data. Identifying equivalents to skip vectors in the corpus network might be achieved using an interface in the form of a raster plot and some kind of "rheostat" input power variation and perhaps input source variation (different parts of the network corresponding to different input sentences.) Assumption is that by varying the driving oscillation we should be able to observe the raster plot and identify clusters of network nodes that are synchronizing and equate these to skip vectors over words associated with the nodes. If we can achieve this I will assess it as a major success. At this stage the skip vector would be limited to single words. Am estimating 1-2 months for this step. But if it took longer it would not be a problem because it would be a major achievement and the major stumbling block to further progress.
Word skip vector equivalents identified using raster plot of oscillations in network of language corpus.
$20,000 USD
Re. what aspects of skip vectors to preserve... I think only their predictive properties. I actually want to not so much preserve them as go beyond skip vectors. I want to go beyond them because I think they will change. I think the fact they change (are dependent on context) is what is holding up language models. And I also want to go beyond them because of and also related to exactly the "arbitrarily far apart" aspect above. Because I think allowing them to change as chaotic attractors should allow us to scrunch up or pull apart sub sequences at will. Like the "keep"->"apart" based skip vector which might consist of words like {keep stay move...} but should also be able to (at a higher energy of synchronization?) break down into k->a k->p... and then also k-(arp)a... skip vectors and overcome the "token" problem which so besets the LLM folks. And in the same way crunch down even more so we get skip vectors for pairs of words and longer... So we'll finally be able to get hierarchy and logical/parse structure. (Though in detail going below words into letters skip vectors/shared context as such probably only influences some broad phonetic effects at the sub-word level and "letters" or phonemes are probably ruled more by things other than skip vector shared context. But above the world level this should enable us to find phrases etc. for the first time. Structure you can use to build an algebra and reason over.)
Skip vectors for "tokens" of variable length. Key to finding hierarchy and ultimately symbolic structure.
$20,000 USD
If we manage to find skip vectors for sequences of varying length this should encode implicit hierarchy in a representation space. This step might be as simple as coding an interface to the raster plot which would graphically represent hierarchies associated with differential clustering between words and word groups varying as driving oscillation power varies.
Graphical or other display of (symbolic) hierarchy in representation space.
$10,000 USD
This is more of a stretch goal. The problems we might face getting the basic underlying principle working may well absorb all our time. But if we do manage to achieve this the next step would be to explicitly integrate the symbolic/hierarchical structure found with representation in Hyperon Atom Space. This might be seen as something of the reverse of a solution like PyNeuraLogic. Instead of implementing logic rules in weights or networks it would use networks to emerge logic relations. The idea is that these have eluded us up to now continue to elude "neuro-" efforts and particularly elude Large Language Models because the structure they seek to "learn" is inherently dynamic and changing. If we embrace the change clear structure will emerge (though change from context to context.) Not only should this be a mapping to a hypergraph representation between "atoms". I would be seen as generating both the representation and the interactions/combinations between "atoms". The idea is that the only reason there has been a tension between neuro- and symbolic historically a puzzle is because structure is chaotic and constantly changing. Embrace the chaos and we should get natural neuro-symbolic representations.
Hyperon Atom Space integration to enable actual reasoning over neurosymbolic representations found using the basic method. Basically the deliverable envisaged is a complete solution to the tension between neuro- and symbolic representations. Which is revealed to have been because cognitive structure consists of chaotic attractors and constantly changes. So deliverable a complete solution to neurosymbolic representation in AI. (With a pathway to other deliverables of chaos: hints at creativity - constant novelty consciousness - chaos "larger than itself" and free will - only the chaotic system fully predicts its own evolution even it's creator cannot fully predict what it will do/discover.) This should be extensible to other experiential learning frameworks. It is not imagined that this dynamic structuring is limited to language. Language would just be the simplest example. In particular it might be immediately applicable to other experiential learning systems like AIRIS.
$4,999 USD
Really getting "stretch" for this project but if budget and time were remaining after an unexpectedly easy accomplishment of the key earlier research milestones a natural next step would be to relate the dynamic skip vectors (incorporating a sense of "attention" because dynamic according to length) to the prediction task which is the one at which current LLMs excel.
Beat LLMs at their own prediction benchmarks but do it with an exposed neurosymbolic hierarchical structure under a Hyperon atom space. Enabling Hyperon to influence sequence completion or other behavioural "predictions" by applying activation differentially to the hierarchical variable length "token" skip vectors associated with input sentences (and eventually other sensory data.)
$1 USD
Please create account or login to post comments.
![]() Reviews & Ratings
Reviews & Ratings
Overall
3.6
3.6
3.8
New reviews and ratings are disabled for Awarded Projects
Overall
3.0
3.0
0.0
Overall
5.0
5.0
0.0
Bold vision and alignment with the RFP’s goals. Lack of detailed technical and experimental plans are concerns. Given the credibility of the researcher this project could be a high-risk, high-reward candidate for funding.
Overall
1.0
1.0
0.0
"Until with language models, finally, all attempt at structure is abandoned completely, in favour of prediction alone. And, surprise surprise, ignoring structure completely, performs best of all." This seems to be a misinterpretation of key results, since attention heads allow to learn multiple structures that matter for an output (e.g. relevant prior words in a sentence to predict a target word), that is part of why they work so well. This approach which dismisses Transformer models seems suspicious to me, and due to the further lack of technical details I gave a low rating. If it would build on top of Transformer it could be a different story, for instance it was quite relevant (but only in light of Transformers and the LLM's) what they found in Bhargava, A., Witkowski, C., Looi, S. Z., & Thomson, M. (2023). What's the Magic Word? A Control Theory of LLM Prompting. arXiv preprint arXiv:2310.04444.
Overall
4.0
5.0
0.0
Freeman is a known entity and a serious researcher and in his own way a visionary thinker. He has been brewing these ideas for a long time. It would be cool to see him experiment with his creative directions in Hyperon. OTOH in the first instance it's not a general-purpose neural-symbolic learning method, it's a novel computational-linguistics idea with deep cognitive/philosophical underpinnings. It might have implications/value beyond language as well.
Overall
5.0
5.0
0.0
Interesting idea with potential for complex systems emergence. Con: unproven and speculative.
© 2025 Deep Funding



Sort by